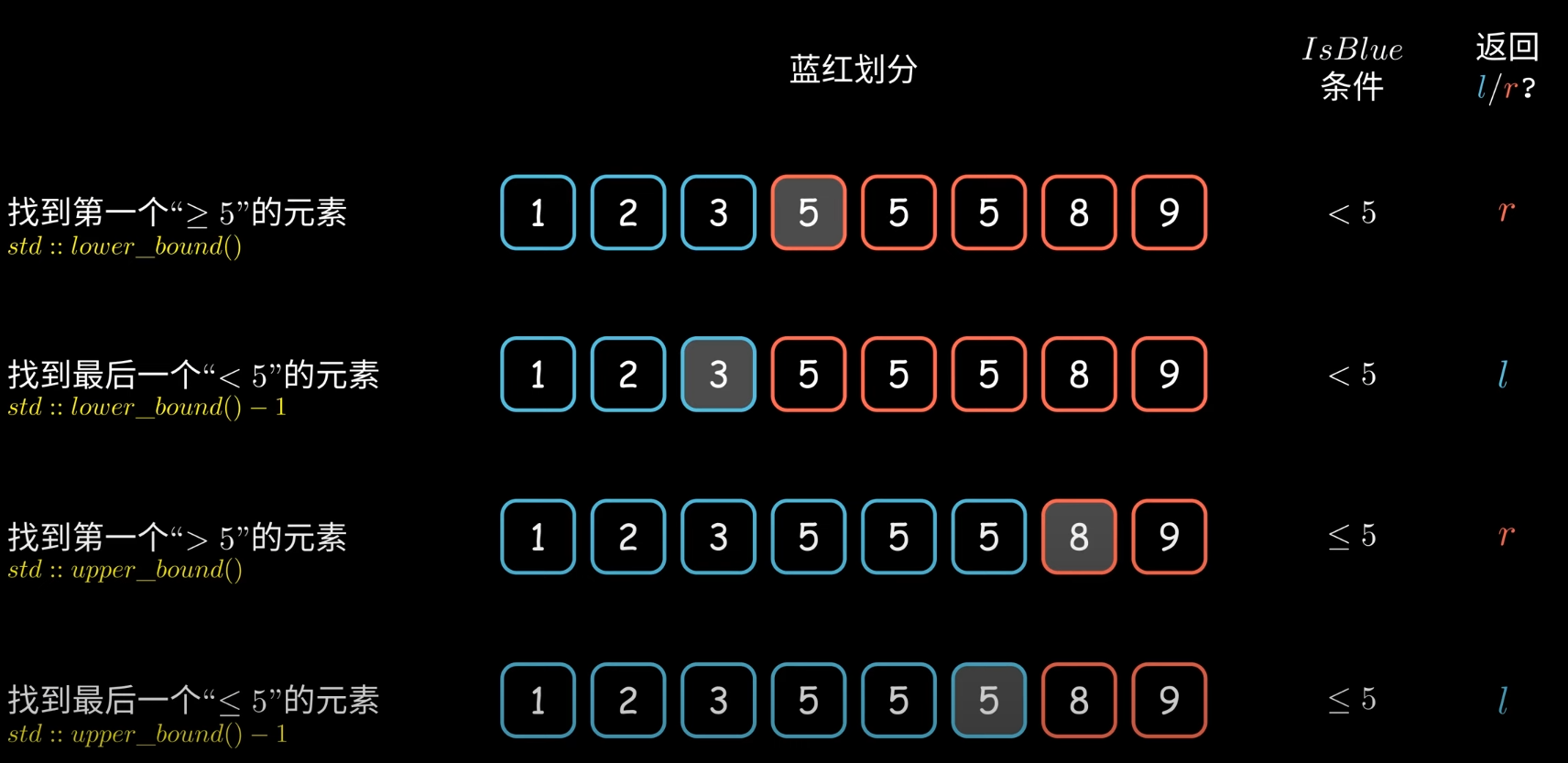
CPP二分查找
蓄水池算法(reservoir sampling)是一种随机算法,用于从数据流中等概率地选择k个元素,其中数据流的大小或数量未知或非常大。该算法适用于需要对数据流进行随机抽样的问题,例如在线随机抽样和统计分析。
在一组数的编码中,若任意两个相邻的代码只有一位二进制数不同,则称这种编码为格雷码(Gray Code),另外由于最大数与最小数之间也仅一位数不同,即“首尾相连”,因此又称循环码或反射码。
遇到poweshell 不识别 nodemon 命令的问题
1 | The term 'nodemon' is not recognized as a name of a cmdlet |
Sometimes,在写代码的过程中,一些variable带有隐私信息,尽管时候在github上删除相关内容,但是在history commit中仍然存在,所以得想其他的办法
【思路】:建立新的分支 -> 删除原本分支 -> 将新分支作为主分支
git checkout --orphan lateset_branch
git add -a
git commit -m 'something u wanna say'
git branch -d master
git branch -m main
git push -f origin main
295场周赛T4,01BFS用到双端队列,之前很少接触这个数据结构
Double-ended queues are sequence containers with the feature of expansion and contraction on both ends.
由此可见,双端队列也就是一个可以在front-end和back-end两端插入或删除的数据罢了
1 | // CPP Program to implement Deque in STL |
Output
1 | The deque gquiz is : 15 20 10 30 |
普通的字符串匹配算法十分直观易懂,但是遇到特殊情况效率极低,因此KMP算法是一种高效的字符串匹配算法
算法的核心思路是减少重复匹配的次数从而降低时间复杂度
普通匹配算法的时间复杂度 O(mn)
KMP算法的时间复杂度 O(m+n)
好久没更新博客了,最近狂刷LeetCode,总结一下遇到的常用的Vector容器的用法
vectorvector<T> arr
n个size的vectorvector<T> arr(int n)
n个size,值全为t的vectorvector<T> arr(int n, T t)
vectorvector<T> arr(vector<T> anotherArr)
vector的一部分vector<T> arr(anotherArr.start(), anotherArr.end())



